
10 Teknik pada Pandas yang Jarang Orang Ketahui
Halo sobat Exsight, gimana nih kabarnya? Pada artikel kali ini, aku diberikan kesempatan lagi nih oleh tim Exsight untuk menjadi penulis tamu. Terima kasih banyak untuk tim Exsight atas kesempatan yang diberikan yah. Buat kalian yang penasaran dengan artikel aku sebelumnya di Exsight, kalian bisa cek artikel aku di link ini yah https://exsight.id/blog/2024/02/24/membuat-mood-tracking-dengan-python/. Di artikel sebelumnya, aku membahas bagaimana caraku melakukan tracking mood dan mengubahnya ke dalam bentuk visualisasi data menggunakan Python.
Nah di artikel kali ini, aku akan bahas 10 teknik pada Pandas yang jarang orang ketahui atau gunakan. Sebagai seseorang yang bekerja di dunia data, pasti familiar dong dengan apa itu library Pandas? Buat yang belum tahu apa itu Pandas, Pandas adalah sebuah library di Python yang sangat terkenal dalam kemudahan penggunaannya untuk memanipulasi ataupun menganalisis data karena memiliki banyak sekali fitur atau fungsi pengolahan data. Karena banyaknya fungsi dan fitur yang tersedia di Pandas, ada banyak “hidden gem” serta tips dan trik menarik yang jarang dibahas atau digunakan, yang sebenarnya bisa meningkatkan level analisis data kita. Tanpa berlama-lama, mari kita masuk ke teknik yang pertama!
1. Fungsi at dan iat
Sebenarnya, Pandas sudah menyediakan dua fungsi yang sangat efisien dan cepat untuk mengakses sebuah value di cell tertentu pada data frame, yaitu at dan iat. Berbeda dengan fungsi loc dan iloc, yang membutuhkan angka untuk mengakses indeks kolom dan baris tertentu, fungsi at dan iat secara langsung bisa mengakses suatu cell berdasarkan nama/indeks kolom dan indeks suatu baris. Hal ini tentu saja sangat berguna dan efisien ketika sobat Exsight ingin menganalisis suatu data dengan jumlah yang besar. Berikut ini adalah contoh code untuk penggunaan beserta output nya:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df.at[0, 'A'])
print(df.iat[1, 1])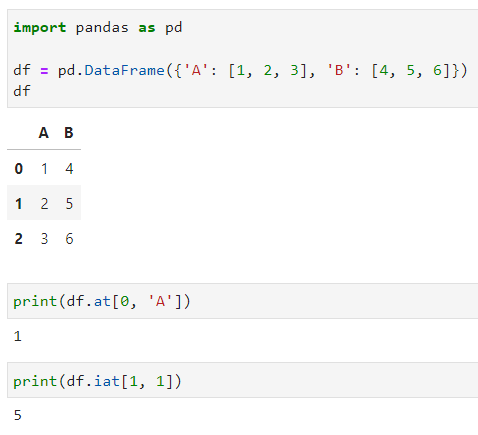
Nah, seperti yang sobat Exsight bisa lihat dari contoh code yang pertama, aku ingin mengambil nilai cell yang ada pada baris pertama di kolom A dengan menggunakan fungsi at. Dari contoh tersebut, dengan menggunakan fungsi at, maka sobat Exsight hanya perlu menuliskan indeks barisnya (baris dengan indeks 0) dan juga nama kolomnya (kolom A).
Contoh selanjutnya, dengan menggunakan fungsi iat, aku ingin mengambil nilai cell yang ada pada baris kedua di kolom B. Maka, dengan menggunakan fungsi iat, sobat Exsight cukup menuliskan indeks barisnya (baris dengan indeks 1) dan juga indeks dari kolom yang ada pada tabel (kolom B memiliki indeks kolom 1). Bagaimana sobat Exsight? Lebih gampang bukan?
2. Data Kategorikal menggunakan astype()
Ketika sobat Exsight yang berhadapan dengan kolom yang memiliki nilai kategorikal, pasti sering dong menggunakan metode str untuk mengonversi kolom nya dari tipe objek menjadi kategorikal? Nah, pada Pandas, sebenarnya sudah tersedia fitur yang lebih efisien untuk mengonversi tipe data kolom ke tipe kategori dengan menggunakan astype("category"). Di bawah ini adalah contoh code penggunaanya:
import pandas as pd
df = pd.DataFrame({'Category': ['Cat', 'Dog', 'Fish'], 'Amount': [2, 5, 3]})
df['Category'] = df['Category'].astype('category')
df.info()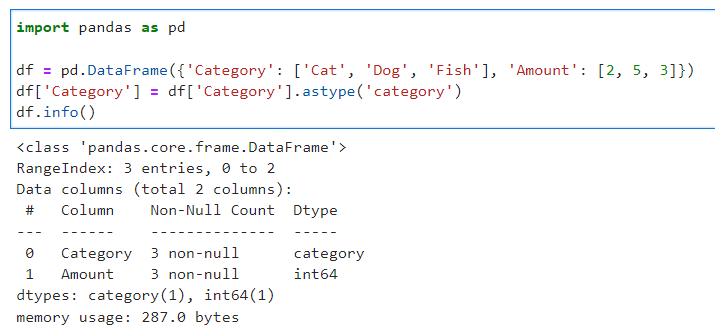
Dari code dan output di atas, dapat dilihat bahwa dengan penggunaan fungsi ini, kolom Category pada dataframe sekarang memiliki tipe data category.
3. Fungsi query()
Selain fungsi loc dan iloc untuk memfilter data, ada fungsi lain yang sudah tersedia di Pandas untuk memfilter data secara ringkas dan efisien, yaitu query(). Dengan menggunakan fungsi ini, sobat Exsight hanya perlu memasukkan query expression saja untuk data yang akan difilter. Lebih mudah bukan? Berikut ini adalah contoh penggunaan dari fungsi query().
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
filtered = df.query('A > 1 and B < 6')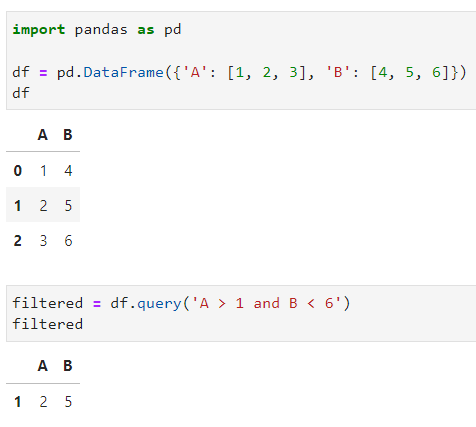
Seperti yang sobat Exsight bisa lihat dari contoh code di atas, aku ingin mendapatkan/filter data dengan kriteria: kolom A memiliki nilai lebih dari 1 dan kolom B memiliki nilai kurang dari 6. Nah, dari kriteria tersebut, sobat Exsight hanya perlu menuliskan query expression-nya seperti pada gambar di atas ("A > 1 and B < 6"). Hal ini tentu saja bisa mempersingkat waktu yang dibutuhkan sobat Exsight untuk memfilter data yang diinginkan, apalagi kalau data yang tersedia cukup besar. Gampang sekali bukan?
4. Fungsi Regex pada str.replace()
Buat sobat Exsight yang sering menggunakan Pandas, pasti sudah sangat familiar dengan fungsi str.replace(). Nah, fungsi ini sangat berguna untuk mengganti suatu string yang ada pada suatu teks atau kolom. Namun, tahukah sobat Exsight, bahwa sebenarnya, fungsi ini juga bisa menerima pola regex loh! Karena fungsi ini bisa menerima pola regex, maka sobat Exsight bisa lebih mudah dan cepat dalam menghandle string yang tidak diinginkan pada suatu teks atau kolom. Di bawah ini adalah contoh code penggunaanya:
import pandas as pd
df = pd.DataFrame({'Text': ['Hello, World!', 'Goodbye, World!']})
df['Text'] = df['Text'].str.replace(r'[^a-zA-Z\s]', '')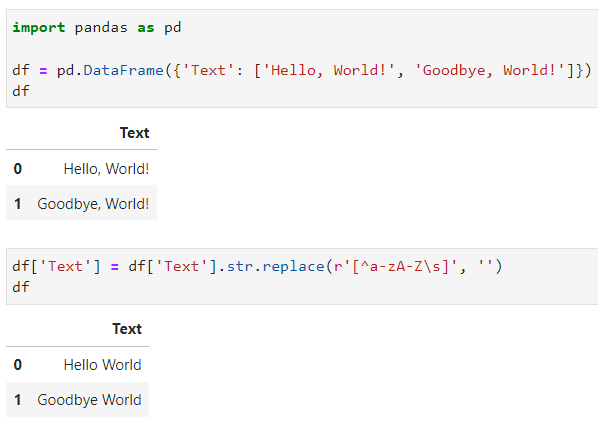
Dari gambar di atas, sobat Exsight bisa lihat nih, value pada data frame yang sebelumnya mengandung simbol-simbol seperti “,” atau “!”, bisa dihilangkan dengan menggunakan pola regex pada fungsi str.replace(). Jadi, sobat Exsight tidak perlu menuliskan satu per satu simbol-simbol yang akan di ganti nantinya, hanya perlu menuliskan pola regex yang akan digunakan untuk menghapus karakter yang tidak diinginkan. Gimana sobat Exsight? Pastinya sangat bermanfaat dong kombinasi antara fungsi str.replace() dan pola regex ini?
5. Indeks Baris dengan isin() dan index()
Pada Pandas, fungsi isin() biasanya digunakan untuk memfilter baris berdasarkan beberapa nilai dalam kolom. Tapi tahukah sobat Exsight, fungsi ini juga dapat digunakan untuk mengekstrak baris berdasarkan nilai indeks loh! Tentu saja hal ini sangat berguna untuk menangani data-data dengan multi-indeks. Di bawah ini adalah contoh code penggunaanya:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3]}, index=['x', 'y', 'z'])
selected_rows = df[df.index.isin(['x', 'z'])]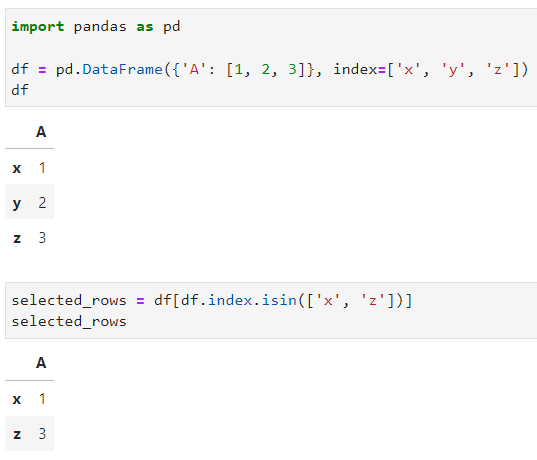
Dari contoh di atas, aku ingin mendapatkan baris yang memiliki indeks “x” dan “z” pada data frame. Nah, sobat Exsight bisa lihat nih dari contoh code di atas, dengan menggunakan kombinasi fungsi index() dan isin(), sobat Exsight hanya perlu menuliskan nama indeks yang akan dicari, dan voilà, baris yang memiliki indeks yang dicari akan langsung dengan gampang ter-filter deh.
6. Konversi Zona Waktu dengan dt.tz_localize() & dt.tz_convert()
Ketika kita berhadapan data-data timestamp, perbedaan zona waktu dari timestamp dapat menjadi tantangan tersendiri dalam pengolahannya. Nah pada Pandas, kedua fungsi ini, yaitu dt.tz_localize() dan dt.tz_convert() bisa menjadi fungsi yang sangat berguna nih bagi sobat Exsight dalam menangani data-data timestamp yang sensitif terhadap zona waktu. Sobat Exsight hanya perlu memasukkan nama zona waktu yang ingin dikonversi. Berikut ini adalah code cara penggunaanya:
import pandas as pd
df = pd.DataFrame({'Timestamp': pd.date_range('2023-08-01', periods=3, tz='UTC')})
df['Timestamp'] = df['Timestamp'].dt.tz_convert('US/Eastern')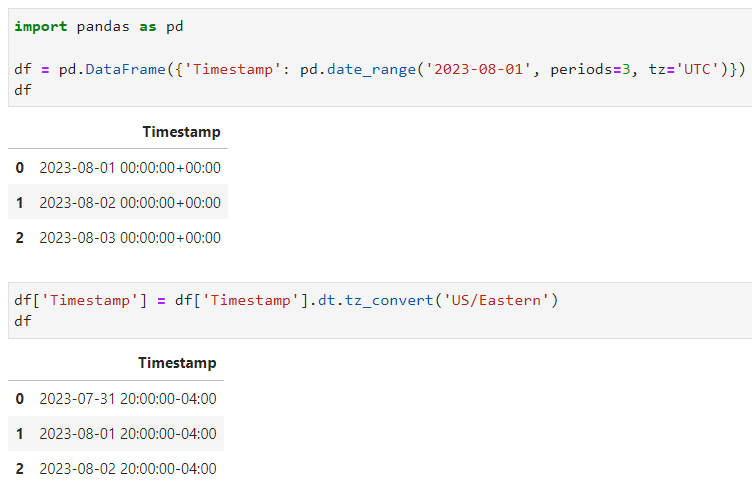
Nah, dari code di atas, aku ingin mengubah zona waktu pada kolom Timestamp yang ada pada dataframe menjadi zona waktu di US/Eastern. Dengan menggunakan fungsi dt.tz_convert(), sobat Exsight bisa langsung menuliskan nama zona waktu nya di dalam fungsi tersebut. Hasilnya, dapat dilihat juga pada gambar di atas bahwa zona waktu pada kolom Timestamp sekarang sudah berubah, yang awalnya +00:00, sekarang sudah menjadi -04:00, sesuai dengan timestamp UTC. Sobat Exsight juga bisa melihat daftar zona waktu dan timestamp UTC yang lain selain “US/Eastern” di link berikut ini yah: https://en.wikipedia.org/wiki/List_of_tz_database_time_zones.
7. Fungsi cut() untuk Binning
Umumnya, fungsi cut() digunakan untuk mengelompokkan data-data kontinyu ke dalam bentuk interval. Namun ternyata, fungsi ini juga bisa digunakan untuk data-data non-numerik, sehingga memungkinkan sobat Exsight untuk membuat binning khusus untuk kolom kategorikal.
import pandas as pd
df = pd.DataFrame({'Age': [25, 32, 45, 18, 67]})
df['AgeGroup'] = pd.cut(df['Age'], bins=[0, 18, 30, 60, float('inf')], labels=['Teen', 'Young Adult', 'Adult', 'Senior'])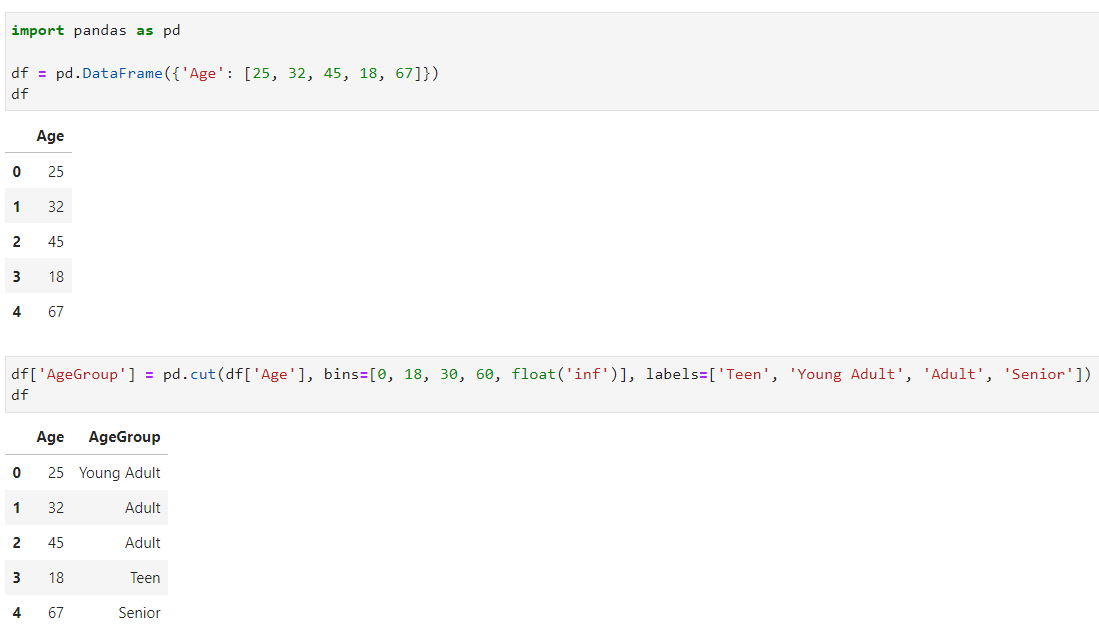
Dari contoh di atas, aku ingin mengelompokan data umur yang ada pada data frame tersebut ke dalam beberapa kelompok umur. Kelompok umur tersebut ada “Teen” (umur 0-18 tahun), “Young Adult” (umur 18-30 tahun), “Adult” (umur 30-60), dan “Senior” (umur 60 tahun ke atas). Untuk itu, dengan menggunakan fungsi cut(), maka kita hanya perlu menuliskan list angka-angka yang menjadi batas umur untuk suatu kelompok umur dengan list label kelompok umur. Fungsi cut() akan membaca angka pertama sebagai batas bawah dari suatu kelompok, dan angka selanjutnya sebagai batas atas untuk kelompok tersebut, dan begitu seterusnya. Nah, seperti yang sobat Exsight bisa lihat juga pada gambar di atas, data-data umur telah sesuai digolongkan ke dalam kelompok umur yang diinginkan.
8. Fungsi read_fwf()
Ketika mengolah data, seringkali data yang kita gunakan datang dalam format fwf (fixed-width formats) dimana data dan kolom tidak dipisahkan oleh delimiter. Untuk mengatasi data dengan format seperti ini, Pandas menyediakan fungsi read_fwf() yang bisa membantu sobat Exsight dalam menentukan lebar kolom dan mengurai datanya secara lebih efisien. Di bawah ini adalah contoh data dan cara penggunaan fungsi tersebut:
"""
> Berikut ini adalah contoh data yang akan digunakan. Data ini akan disimpan ke dalam file bernama "data.txt".
Datanya:
Spark 15000 Day3
Pandas 20000 Day4
Python 25000 Day6
"""
import pandas as pd
col_specs = [(0, 6), (6, 12), (12, 17)]
df = pd.read_fwf('data.txt', colspecs=col_specs, names=['A', 'B', 'C'])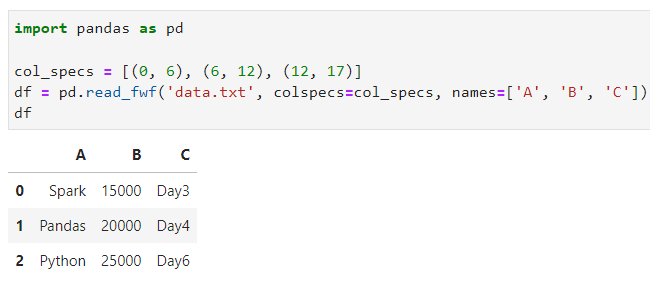
Nah, dari contoh di atas sobat Exsight bisa lihat nih, hanya dengan menentukan lebar kolom berdasarkan posisi/indeks karakter di variabel col_specs, serta memberikan list nama kolom, data-data yang ada dalam file TXT telah terpisahkan dengan benar.
9. Seleksi Indeks menggunakan nlargest() dan nsmallest()
Mungkin sebagian dari sobat Exsight pasti baru pertama kali nih mendengar kedua fungsi ini, yaitu nlargest() dan nsmallest(). Jadi, fungsi nlargest() ini berguna sekali untuk menunjukkan banyaknya baris pertama (sejumlah n) dengan nilai terbesar dari suatu kolom, dalam urutan menurun. Sedangkan fungsi nsmallest() adalah sebaliknya, dimana fungsi ini menunjukkan banyaknya baris pertama (sejumlah n) dengan nilai terkecil dari suatu kolom, dalam urutan menaik. Berikut ini adalah contoh dari penggunaan fungsi nlargest() beserta outputnya.
import pandas as pd
df = pd.DataFrame({'Category': ['A', 'B', 'C', 'D'], 'Value': [10, 25, 15, 30]})
top_2 = df.nlargest(2, 'Value')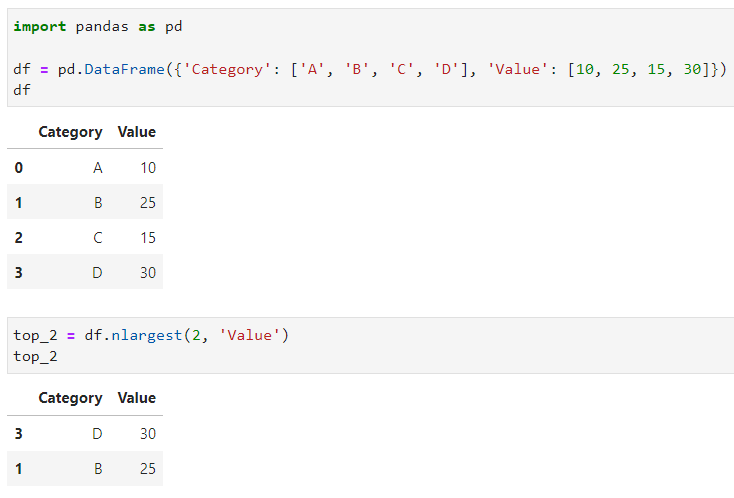
Pada contoh di atas, aku ingin mencari 2 data yang memiliki angka terbesar pada kolom “Value” di data frame. Nah, dengan menggunakan fungsi nlargest(), sobat Exsight hanya perlu menentukan berapa baris yang akan dicari pada data frame beserta nama kolom yang akan diurutkan. Dari contoh tersebut, sobat Exsight tinggal menuliskan 2 sebagai jumlah barisnya, dan kolom “Value” sebagai kolom yang akan diurutkan. Mudah bukan?
10. Kegunaan lain dari merge()
Kalau fungsi ini, aku yakin sobat Exsight pasti sering gunakan kalau ingin menggabungkan dua data frame menjadi satu data frame. Namun, ternyata fungsi merge() pada Pandas tidak hanya bisa menggabungkan kedua data frame saja loh! Sobat Exsight juga bisa melakukan operasi yang lebih rumit seperti menggabungkan beberapa kolom dan menggabungkan nama kolom berbeda di dua data frame. Di bawah ini adalah contoh code cara penggunaanya:
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'C': [1, 2, 3], 'D': [7, 8, 9]})
merged_df = df1.merge(df2, left_on='A', right_on='C')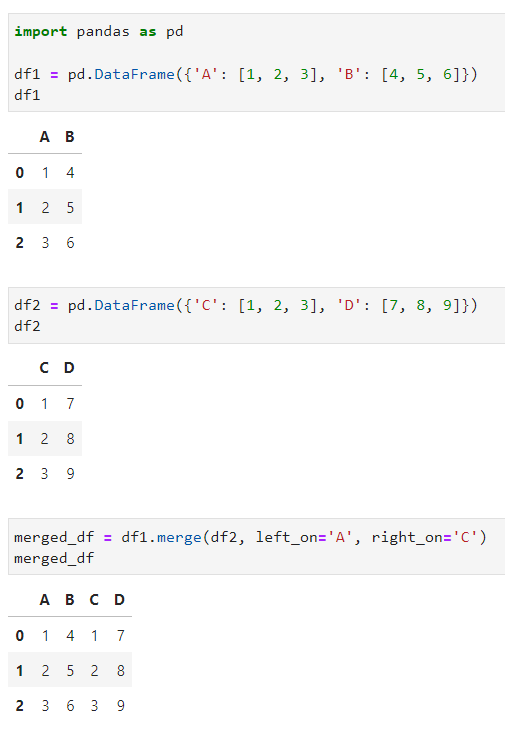
Nah, pada contoh di atas, aku ingin menggabungkan data frame pertama (df1) dengan data frame kedua (df2). Dengan menggunakan fungsi merge(), maka sobat Exsight dapat menspesifikasikan lebih detail lagi bagaimana proses penggabungan antara kedua data frame ini dilakukan. Pada contoh di atas, aku menggunakan parameter left_on, dimana kolom dari data frame pertama untuk digunakan sebagai kunci, dan juga right_on, dimana kolom dari data frame kedua digunakan sebagai kunci. Nah, dengan begitu, dengan menggunakan kolom A pada data frame pertama sebagai kunci untuk parameter left_on, dan kolom C pada data frame kedua sebagai kunci untuk parameter right_on, maka hasil dari proses penggabungannya dapat dilihat pada gambar di atas.
Penutup
Jadi itulah 10 teknik pada Pandas yang mungkin orang jarang ketahui atau gunakan. Dari ke 10 teknik tadi, kira-kira mana nih yang sobat Exsight merasa paling berguna atau baru tahu? Kalian bisa langsung komen di bawah ya! Oh ya, jika kalian tahu teknik-teknik lain selain 10 teknik di atas, kita juga bisa berdiskusi bareng di kolom komentar juga yah!
Itu aja yang aku bisa sharing ke sobat Exsight buat artikel kali ini. Kalian bisa follow atau connect LinkedIn aku di https://www.linkedin.com/in/caesarmario/ jika kalian ingin tahu informasi-informasi terbaru dari project-project data yang aku buat. Stay tuned terus di website https://exsight.id/blog/ agar tidak ketinggalan artikel-artikel menarik lainnya. Sampai jumpa!
Referensi
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.iat.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.at.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.astype.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.query.html
- https://stackoverflow.com/questions/22588316/pandas-applying-regex-to-replace-values
- https://pandas.pydata.org/docs/reference/api/pandas.Index.isin.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html
- https://pandas.pydata.org/docs/reference/api/pandas.read_fwf.html
- https://note.nkmk.me/en/python-pandas-cut-qcut-binning/
- https://pandas.pydata.org/docs/reference/api/pandas.Series.tz_localize.html
- https://pandas.pydata.org/docs/reference/api/pandas.Series.dt.tz_convert.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.nlargest.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.nsmallest.html
- https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
10 Teknik pada Pandas yang Jarang Orang Ketahui Read More »
















