

Hai sobat Exsight, kembali lagi pada segmen artikel tutorial. Nah untuk tutorial ini, kita akan membahas terkait bagaimana cara kerja algoritma Naive Bayes menggunakan software R. Kalau sobat Exsight masih bingung terkait apa itu Naive Bayes, bisa dilihat pada artikel sebelumnya dengan judul Algoritma Naive Bayes dalam Machine Learning #1.
Studi Kasus
Studi kasus yang akan kita gunakan dalam hal ini menggunakan data sampel terkait Lung Cancer (Kanker Paru-Paru) yang didapatkan dari situs kaggle.com, dimana data di-publish oleh Ms. Nancy Al Aswad.
* Tidak terdapat missing value pada data.
* Data terdiri atas 309 observasi.

Data terdiri atas 16 variabel yaitu:
| Variabel | Keterangan Variabel | Skala Data |
| Gender | M = Male F = Female | Kategorik |
| Age | Numerik | |
| Smoking | 1 = No 2 = Yes | Kategorik |
| Yellow Finger | 1 = No 2 = Yes | Kategorik |
| Anxiety | 1 = No 2 = Yes | Kategorik |
| Peer Pressure | 1 = No 2 = Yes | Kategorik |
| Chronic Disease | 1 = No 2 = Yes | Kategorik |
| Fatigue | 1 = No 2 = Yes | Kategorik |
| Allergy | 1 = No 2 = Yes | Kategorik |
| Wheezing | 1 = No 2 = Yes | Kategorik |
| Alcohol | 1 = No 2 = Yes | Kategorik |
| Coughing | 1 = No 2 = Yes | Kategorik |
| Shortness of Breath | 1 = No 2 = Yes | Kategorik |
| Swallowing Difficulty | 1 = No 2 = Yes | Kategorik |
| Chest Pain | 1 = No 2 = Yes | Kategorik |
| Lung Cancer | 1 = No 2 = Yes | Kategorik |
Pada Tabel 1. variabel Lung Cancer berperan sebagai variabel Dependen, sedangkan lainnya merupakan variabel Independen.
Tahapan R Studio Naive Bayes
Load Library
Tahapan paling awal sebelum running syntax di software R yaitu melakukan load library R. Adapun library yang diperlukan untuk analisis jalur yaitu e1071 dan caret. Adapun syntax R yang digunakan adalah sebagai berikut.
library(e1071)
library(caret)Load Data
Kemudian melakukan input data ke R. Data yang diinput diberi nama sebagai data. Perlu diperhatikan untuk jenis file data yang diinput ke R, untuk tutorial kali ini, jenis file data yang digunakan yaitu dalam format CSV. Syntax yang digunakan untuk load data adalah sebagai berikut.
data<-read.csv(file.choose(),header=TRUE,sep=",")Pre-Processing
Data yang telah kita load selanjutnya kita split menjadi data training testing 80/20. Artinya dari data yang ada, 80% dari data kita jadikan sebagai data training dan 20% data kita jadikan data testing.
##Membuat data training dan data testing (training 80, testing 20)
n_train <- round(nrow(data) * 0.8)
idx_train <- sample(seq_len(n_train))
data_train <- data[idx_train, ]
data_test <- data[-idx_train, ]
#Menyimpan data hasil training dan testing dalam format csv
write.csv(data_train,"training.csv")
write.csv(data_test,"testing.csv")
#Membuka file hasil training dan testing
data_train=read.csv(file.choose(),header=TRUE,sep=",")
data_test=read.csv(file.choose(),header=TRUE,sep=",")Selanjutnya mengacu pada Tabel 1. variabel dengan skala data “kategorik” baik pada data training dan data testing, kita pastikan tipe data menjadi “factor” di R.
#Mengubah tipe data
##Data Train
data_train$GENDER=as.factor(data_train$GENDER)
data_train$SMOKING=as.factor(data_train$SMOKING)
data_train$YELLOW_FINGERS=as.factor(data_train$YELLOW_FINGERS)
data_train$ANXIETY=as.factor(data_train$ANXIETY)
data_train$PEER_PRESSURE=as.factor(data_train$PEER_PRESSURE)
data_train$CHRONIC.DISEASE=as.factor(data_train$CHRONIC.DISEASE)
data_train$FATIGUE=as.factor(data_train$FATIGUE)
data_train$ALLERGY=as.factor(data_train$FATIGUE)
data_train$WHEEZING=as.factor(data_train$WHEEZING)
data_train$ALCOHOL.CONSUMING=as.factor(data_train$ALCOHOL.CONSUMING)
data_train$COUGHING=as.factor(data_train$COUGHING)
data_train$SHORTNESS.OF.BREATH=as.factor(data_train$SHORTNESS.OF.BREATH)
data_train$SWALLOWING.DIFFICULTY=as.factor(data_train$SWALLOWING.DIFFICULTY)
data_train$CHEST.PAIN=as.factor(data_train$CHEST.PAIN)
data_train$LUNG_CANCER=as.factor(data_train$LUNG_CANCER)
##Data Test
data_test$GENDER=as.factor(data_test$GENDER)
data_test$SMOKING=as.factor(data_test$SMOKING)
data_test$YELLOW_FINGERS=as.factor(data_test$YELLOW_FINGERS)
data_test$ANXIETY=as.factor(data_test$ANXIETY)
data_test$PEER_PRESSURE=as.factor(data_test$PEER_PRESSURE)
data_test$CHRONIC.DISEASE=as.factor(data_test$CHRONIC.DISEASE)
data_test$FATIGUE=as.factor(data_test$FATIGUE)
data_test$ALLERGY=as.factor(data_test$FATIGUE)
data_test$WHEEZING=as.factor(data_test$WHEEZING)
data_test$ALCOHOL.CONSUMING=as.factor(data_test$ALCOHOL.CONSUMING)
data_test$COUGHING=as.factor(data_test$COUGHING)
data_test$SHORTNESS.OF.BREATH=as.factor(data_test$SHORTNESS.OF.BREATH)
data_test$SWALLOWING.DIFFICULTY=as.factor(data_test$SWALLOWING.DIFFICULTY)
data_test$CHEST.PAIN=as.factor(data_test$CHEST.PAIN)
data_test$LUNG_CANCER=as.factor(data_test$LUNG_CANCER)
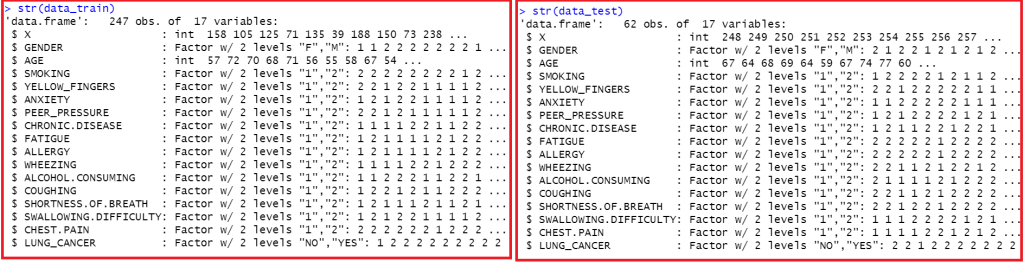
Berikutnya, kita perhatikan kembali data training dan testing, kita hilangkan kolom yang tidak perlu, dalam hal ini kolom pertama (x) yang hanya menunjukkan urutan observasi.
#Removing Kolom "Nomor urut di awal data train & test"
data_train=data_train[,-1]
data_test=data_test[,-1]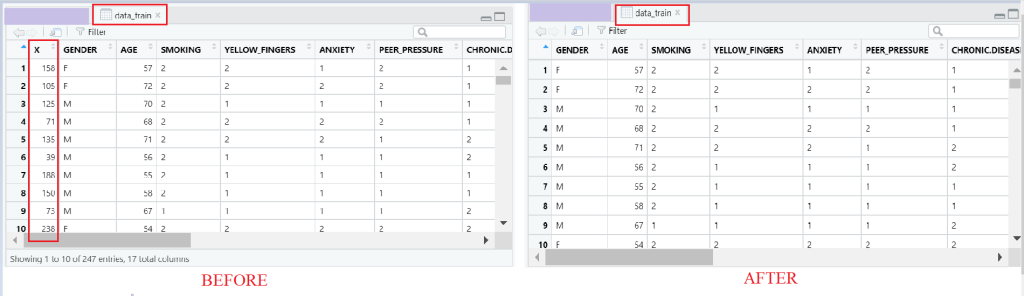
Pemodelan
Setelah melakukan Pre-Processing, tahapan berikutnya melakukan pemodelan Naive Bayes untuk data training dengan syntax sebagai berikut.
model<-naiveBayes(LUNG_CANCER~.,data=data_train)
model
Gambar 3. menunjukkan hasil pemodelan Naive Bayes pada data Training yaitu berupa Priori Probabilities dan Conditional Probabilities pada setiap variabel.
Selanjutnya, melakukan prediksi pada data Testing, dalam hal ini kita menentukan nilai probabilitas untuk pengkategorian “NO” dan “YES” pada data Lung Cancer, selengkapnya dapat dilihat pada Gambar 4.
# Generating the probabilities in prediction
ypred<-predict(model, newdata = data_test, type="raw")
ypred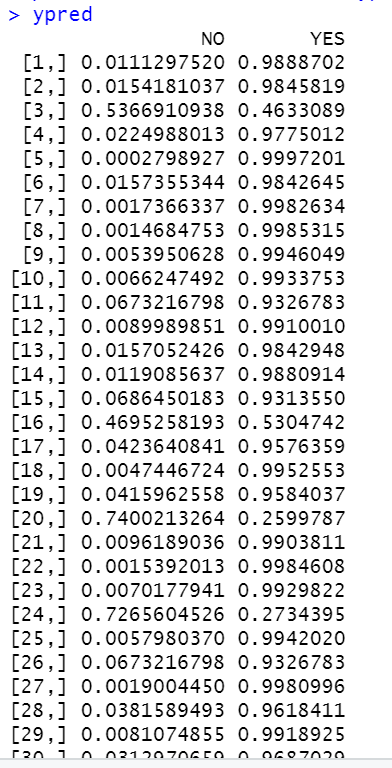
Berdasarkan Gambar 4, apabila probabilitas di kategori “YES” lebih tinggi dibandingkan kategori “NO”, artinya hasil prediksi pada data Testing masuk ke kategori “YES”. Selengkapnya untuk melihatkan hasil prediksi Naive Bayes pengkategorian kelas pada data Testing dapat dilihat pada Gambar 5. sebagai berikut.
# Generating the class in prediction
pred<-predict(model,newdata=data_test)
plot(pred)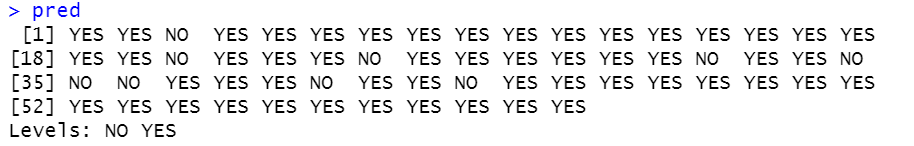
Langkah terkahir yaitu menentukan Confusion Matrix, dengan syntax sebagai berikut.
# Confusion Matrix
caret::confusionMatrix(pred,reference=data_test$LUNG_CANCER)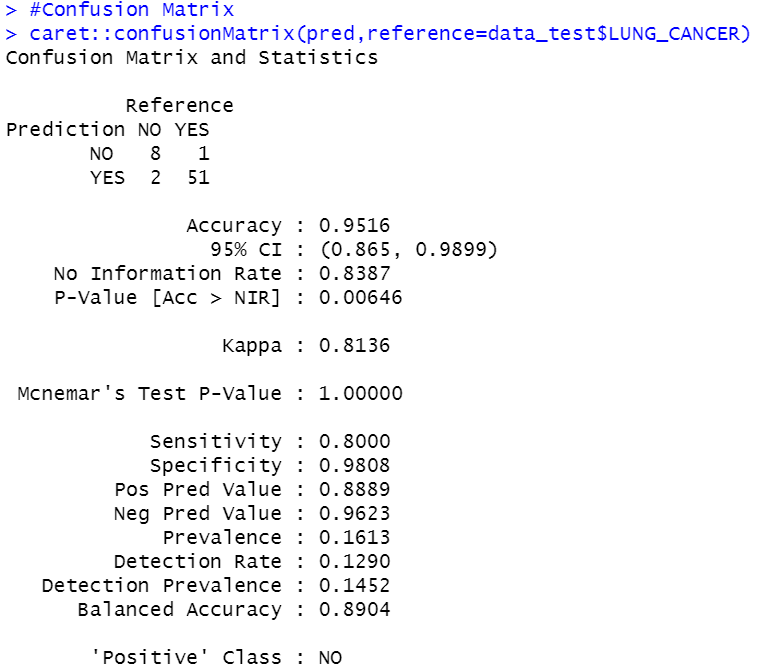
Berdasarkan Gambar 6. diketahui bahwa dengan menggunakan algoritma Naive Bayes , hasil klasifikasi terkait data Lung Cancer memiliki accuracy yang sangat baik yaitu sebesar 0,9516 , lalu sensitivity sebesar 0,8000 , dan specificity sebesar 0,9808.
Dalam hal ini:
* Accuracy menunjukkan sejauh mana model Naive Bayes mampu mengklasifikasikan data dengan benar secara keseluruhan. Accuracy menghitung jumlah prediksi yang benar (true positives dan true negatives) dibagi oleh jumlah total data.
*Sensitivity menunjukkan sejauh mana model Naive Bayes mampu mengidentifikasi jumlah prediksi yang benar positif (true positive) dalam dataset..
*Specificity menunjukkan sejauh mana model Naive Bayes mampu mengidentifikasi jumlah prediksi yang benar negatif (true negative) dalam dataset.
Referensi
Sampai disini dulu penjelasan terkait Tutorial Algoritma Naive Bayes dengan Software R. Jika masih ada yang dibingungkan bisa langsung saja ramaikan kolom komentar atau hubungi admin melalui tombol bantuan di kanan bawah. Stay tuned di website https://exsight.id/blog/ agar tidak ketinggalan artikel-artikel menarik lainnya.
