

Hai sobat Exsight! Selamat datang di artikel kami. Pada artikel sebelumnya, kita telah membahas konsep dasar mengenai Multidimensional Scaling (MDS) dan kita juga telah mempelajari tutorial Multidimensional Scaling dengan SPSS. Nah selanjutnya kita akan mempelajari menggunakan Multidimensional Scaling (MDS) jika dengan bahasa pemrograman python.
Sebelum itu alangkah baiknya kita mengingat kembali mengenai Multidimensional Scaling (MDS). Nah apa sih Multidimensional Scaling (MDS) itu? Multidimensional Scaling (MDS) adalah sebuah teknik analisis statistik multivariat yang digunakan untuk menggambarkan struktur hubungan antar objek data berdasarkan kemiripannya secara grafis dalam suatu bidang multidimensi, untuk mendapatkan informasi dari data.
Okay dari sini kita mulai bertanya-tanya apa sih sebenarnya tujuan dari Multidimensional Scaling (MDS). Sebenarnya tujuan dari Multidimensional Scaling (MDS) adalah untuk mengurai data yang kompleks sehingga bisa menjadi data yang lebih sederhana. Hal ini dilakukan melalui reduksi dimensi data, menganalisis struktur data, mengukur kesamaan antara objek, serta memvisualisasikan hubungan antara objek sehingga dapat membantu dalam analisis pengambilan keputusan.
Pasti masih banyak pertanyaan yang muncul dibenak kalian bukan? Mengenai konsep dasarnya, jenis-jenis Multidimensional Scaling hingga Kelebihan dan Keterbatasan. Nah sobat bisa langsung ke artikel kami yang berjudul “Tutorial Multidimensional Scaling dengan SPSS #2” agar lebih mantap pemahamannya sehingga bisa menjadi pondasi untuk melakukan tutorial Multidimensional Scaling (MDS) dengan Python.
Mari kita simak tutorial Multidimensional Scaling (MDS) dengan Python secara cermat !!
Studi Kasus

Pada tahun 2019, Pemerintah Kabupaten Jombang, Jawa Timur, melakukan evaluasi terhadap indikator lingkungan dan kesehatan di wilayahnya untuk mendukung perencanaan kebijakan yang lebih efektif. Data yang digunakan dalam studi ini mencakup indikator-indikator penting yang mencerminkan kualitas lingkungan dan layanan kesehatan masyarakat. Penelitian ini bertujuan untuk memahami pola kesamaan atau perbedaan antarwilayah di Kabupaten Jombang dengan menggunakan metode Multidimensional Scaling (MDS).
Data yang dianalisis terdiri dari 5 variabel prediktor: persentase penduduk dengan sanitasi layak (X1), persentase sarana air minum yang memenuhi syarat kesehatan (X2), persentase tempat-tempat umum yang memenuhi syarat kesehatan (X3), persentase pelayanan kesehatan untuk penduduk usia produktif (X4), dan persentase pelayanan kesehatan untuk penduduk usia lanjut (X5). Variabel-variabel ini diukur untuk beberapa wilayah administratif, tanpa adanya nilai yang hilang dalam dataset, sehingga memungkinkan analisis langsung menggunakan Multidimensional Scaling (MDS).
Tujuan dari analisis ini adalah untuk memetakan wilayah-wilayah berdasarkan indikator-indikator tersebut ke dalam ruang dua dimensi. Visualisasi yang dihasilkan akan menunjukkan kedekatan antarwilayah, di mana wilayah-wilayah yang memiliki pola indikator yang serupa akan terlihat lebih dekat satu sama lain dalam grafik. Sebaliknya, wilayah yang berjauhan menunjukkan perbedaan signifikan dalam karakteristik lingkungan dan kesehatannya.
Data tersebut dapat diakses disini!
Tutorial Multidimensional Scaling (MDS) dengan Python #1
Berikut adalah tutorial lengkap untuk melakukan analisis Multidimensional Scaling (MDS) menggunakan Python dengan data lingkungan dan kesehatan yang telah disediakan. Tutorial ini mencakup langkah-langkah untuk mempersiapkan data, menerapkan Multidimensional Scaling (MDS), dan memvisualisasikan hasilnya. Selanjutnya melakukan interpretasi pada output yang didapatkan.
Langkah 1: Impor Library yang Diperlukan
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.manifold import MDS
from sklearn.metrics import pairwise_distancesSebenarnya Library diatas berfungsi untuk apa sih? Nah fungsi-fungsi nya yaitu sebagai berikut :
- NumPy : Digunakan untuk berbagai operasi numerik, termasuk manipulasi array dan perhitungan matriks.
- Pandas: Memudahkan pengolahan dan analisis data dalam bentuk tabel, seperti DataFrame.
- Matplotlib.pyplot: Library yang digunakan untuk membuat berbagai jenis visualisasi data, termasuk scatter plot.
- Scikit-learn (sklearn.manifold.MDS): Memfasilitasi penerapan Multidimensional Scaling (MDS) untuk mereduksi dimensi data.
- Scikit-learn (sklearn.metrics.pairwise_distances): Berfungsi untuk menghitung jarak antar data dalam bentuk matriks, yang berguna dalam analisis berbasis kedekatan atau kemiripan.
Langkah 2: Mempersiapkan Data
Selanjutnya buat dataFrame. Siapkan data dalam format yang sesuai menggunakan pandas DataFrame. Data yang akan digunakan mencakup informasi tentang kecamatan, persentase penduduk dengan sanitasi layak, sarana air minum, tempat umum, dan layanan kesehatan.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.manifold import MDS
from sklearn.metrics import pairwise_distances
# Data lingkungan dan kesehatan
data = {
"Kecamatan": [
"Bandar Kedungmulyo", "Perak", "Gudo", "Diwek", "Ngoro", "Mojowarno",
"Bareng", "Wonosalam", "Mojoagung", "Sumobito", "Jogoroto",
"Peterongan", "Jombang", "Megaluh", "Tembelang", "Kesamben",
"Kudu", "Ngusikan", "Ploso", "Kabuh", "Plandaan"
],
"X1_%Penduduk Sanitasi Layak": [
97.3, 100, 99.4, 99.3, 100, 88.05, 77.5, 62.9, 96.75, 99.35, 93.55,
99.55, 100, 94.9, 95.9, 97.6, 92.9, 93.4, 97.9, 71.8, 77.4
],
"X2_% Sarana Air Minum": [
100, 0, 85.4, 83.35, 65.7, 44.05, 75, 0, 50, 90, 66.7, 75, 85.4, 100,
71.45, 100, 100, 0, 80, 66.7, 100
],
"X3_% Tempat Umum": [
41, 86, 75.9, 57.85, 66.6, 66.45, 59.3, 66.7, 61.35, 82.8, 60.05,
83.15, 84.58, 87.8, 68.75, 66.5, 42.2, 59.6, 39.4, 85.2, 65.5
],
"X4_% Pelayanan Usia Produktif": [
33.2, 1.9, 43.15, 39.8, 20.45, 20.35, 11.1, 18.3, 32.6, 20, 38.9,
15.15, 14.375, 49.1, 56.15, 34.65, 98, 26.7, 13.9, 22, 15.5
],
"X5_% Pelayanan Usia Lanjut": [
44.6, 7.3, 55.75, 48.45, 47.05, 48.4, 106.3, 42.5, 56.65, 143.15,
39.75, 58.05, 42.425, 92.2, 35.6, 67.75, 48.9, 68.9, 48.7, 21.7, 30.1
]
}
# Membuat DataFrame
df = pd.DataFrame(data)
# Menetapkan kolom Kecamatan sebagai indeks
df.set_index('Kecamatan', inplace=True)
# Menampilkan 5 data teratas dari DataFrame
print("Data Lingkungan dan Kesehatan (5 Teratas):\n", df.head())Dari sintaks di atas kita tidak menampilkan data secara menyeluruh. Namun, hanya 5 data teratas saja dengan menggunakan fungsi df.head() . Output yang didapatkan sebagai berikut:
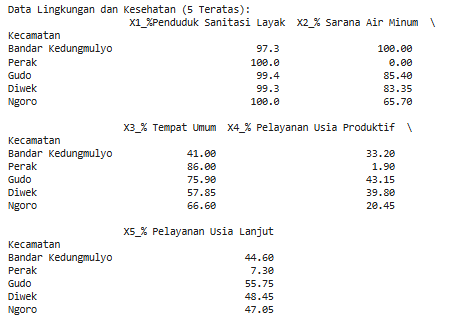
Langkah 3: Menghitung Jarak Asli
original_distances = pairwise_distances(df, metric='euclidean')Sintaks ini digunakan menghitung jarak antara setiap kecamatan berdasarkan metrik Euclidean. Matriks jarak ini digunakan sebagai input untuk MDS.
Langkah 4: Menerapkan Multidimensional Scaling (MDS)
Langkah kedua yaitu kita akan menggunakan Multidimensional Scaling (MDS) untuk mereduksi data. Hal ini dilakukan dengan mengimpor Multidimensional Scaling (MDS) dari scikit-learn.
mds = MDS(n_components=2, random_state=0, dissimilarity='precomputed')
scaled_df = mds.fit_transform(original_distances)
# Menampilkan hasil MDS
print("\nHasil Multidimensional Scaling:\n", scaled_df)Sobat dapat lihat bahwa sintaks di atas menggunakan parameter random_state . Parameter random_state ini digunakan untuk mengatur reproduksibilitas hasil dari proses pengacakan yang mungkin terjadi selama pelaksanaan algoritma Multidimensional Scaling (MDS). Dengan menetapkan random_state ke nilai tertentu (dalam tutorial ini yaitu 0), kita dapat memastikan bahwa setiap kali kita menjalankan kode ini, output Multidimensional Scaling (MDS) yang dihasilkan akan konsisten. Ini penting jika kita ingin mendapatkan hasil yang sama setiap kali menjalankan analisis, sehingga lebih mudah untuk membandingkan hasil antara eksperimen yang berbeda.
Kemudian untuk parameter n_components digunakan untuk menyatakan bahwa hasilnya dalam dua dimensi. Selanjutnya yang parameter sangat penting juga yaitu dissimilarity dalam sintaks di atas mengacu pada jenis jarak yang digunakan untuk menghitung ketidaksamaan (dissimilarity) antara titik-titik data. dissimilarity=’precomputed’ menunjukan bahwa kita sedang menggunakan jarak yang sudah dihitung sebelumnya. Jenis jarak apakah itu ? Yups… jarak yang kita gunakan adalah jarak euclidean
Sebenarnya apa sih jarak Euclidean itu?
Jadi, jarak Euclidean itu adalah salah satu cara yang paling umum untuk mengukur jarak antara dua titik dalam ruang multidimensi. Ini dihitung dengan menggunakan rumus Pythagoras, yang memberikan hasil jarak garis lurus antara dua titik. Dalam konteks MDS, jarak ini digunakan untuk menentukan seberapa dekat atau jauh dua objek berdasarkan atribut yang mereka miliki.
Output yang didapatkan dari sintaks di atas yaitu sebagai berikut:
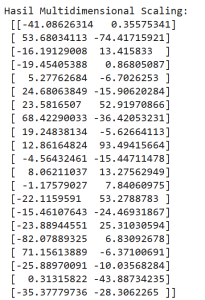
Dari perhitungan jarak Euclidean didapatkan output seperti di atas. Output di atas adalah koordinat dimana kolom pertama untuk sumbu x dan kolom kedua untuk sumbu y.
Langkah 5: Menghitung Nilai Stress
Untuk menilai kualitas MDS, kita menghitung Kruskal’s Stress, yang menunjukkan seberapa baik hasil reduksi dimensi ini mempertahankan hubungan antar kecamatan.
mds_distances = pairwise_distances(scaled_df, metric='euclidean')
stress_manual = 0.5 * np.sum((mds_distances - original_distances) ** 2)
stress_kruskal = np.sqrt(stress_manual / (0.5 * np.sum(original_distances ** 2)))
print("\nNilai Stress dari Scikit-Learn:", mds.stress_)
print("Manual Stress Calculation:", stress_manual)
print("Kruskal's Stress:", stress_kruskal)
print("[Poor > 0.2 > Fair > 0.1 > Good > 0.05 > Excellent > 0.025 > Perfect > 0.0]")Dari sintaks diatas kita mendapatkan output sebagai berikut :

Dapat dilihat bahwa nilai Kruskal’s Stress sebesar 0.14 sehingga dapat masuk pada kategori fair>0.1. Dengan kata lain dapat dikatakan bahwa hasil cukup baik. Hasil ini bisa digunakan, tetapi ada distorsi yang cukup besar.
Jika sobat ingin hasil yang lebih baik sobat dapat mencoba beberapa kombinasi parameter lainnya sampai mendapatkan nilai Stress yang sangat kecil atau bahkan mendapatkan nilai 0.
Langkah 6: Visualisasi Hasil Multidimensional Scaling (MDS)
Langkah ketiga yaitu mengimport Matplotlib untuk Visualisasi. Hal ini digunakan untuk membuat scatterplot dari hasil Multidimensional Scaling (MDS).
import matplotlib.pyplot as plt
# Membuat scatterplot hasil MDS
plt.figure(figsize=(10, 8))
plt.scatter(scaled_df[:, 0], scaled_df[:, 1], c='blue', s=100)
# Menambahkan label pada tiap titik
for i, kecamatan in enumerate(df.index):
plt.annotate(kecamatan, (scaled_df[i, 0] + 0.3, scaled_df[i, 1]), fontsize=9)
# Menambahkan garis pemisah kuadran
plt.axhline(0, color='red', lw=1, ls='--') # Garis horizontal
plt.axvline(0, color='red', lw=1, ls='--') # Garis vertikal
# Menambahkan judul dan label sumbu
plt.title('Multidimensional Scaling (MDS) pada Data Lingkungan dan Kesehatan', fontsize=14)
plt.xlabel('Koordinat 1', fontsize=12)
plt.ylabel('Koordinat 2', fontsize=12)
plt.grid()
plt.xlim(-100, 100) # Mengatur batas sumbu x
plt.ylim(-100, 100) # Mengatur batas sumbu y
plt.show()Output yang didapatkan dari sintaks di atas yaitu sebagai berikut:

Dari sini kita dapat simpulkan bahwa titik yang berdekatan memiliki karakteristik yang mirip. Seperti wilayah Kesamben dengan wilayah Gudo. Kemudian, wilayah yang paling tidak mirip yaitu wilayah Kudu dengan Ngusikan.
Berdasarkan hasil output Python. Jika dilihat dari grafik secara keseluruhan, terdapat empat kelompok kecamatan yang memiliki kemiripan antar anggotanya, namun berbeda dengan kelompok lainnya.
*Kelompok 1 (Kuadran 1 bagian kiri atas)
Terdiri atas 7 kecamatan, yaitu Kecamatan Megaluh, Kesamben, Kudu, Gudo, Bandar Kedungmulyo, Jombang dan Diwek. 7 Kecamatan tersebut dapat dilihat memiliki persamaan karakteristik dari penduduk sanitasi layak dan sarana air minum sehingga berada dalam 1 kuadran. Hal ini dapat dilihat juga dari data aslinya dimana pada dua karakteristik ini memiliki nilai yang lebih tinggi dibanding nilai karakteristik lainnya.
*Kelompok 2 (Kuadran 2 bagian kanan atas)
Terdiri atas 3 kecamatan, yaitu Kecamatan Sumobito, Bareng, dan Peterongan. 3 Kecamatan tersebut dapat dilihat memiliki persamaan karakteristik dari segi pelayanan usia produktif sehingga berada dalam 1 kuadran. Hal ini dapat dilihat juga dari data aslinya dimana pada karakteristik ini kecamatan tersebut memiliki nilai yang paling rendah dibanding nilai karakteristik lainnya.
*Kelompok 3 (Kuadran 3 bagian kiri bawah)
Terdiri atas 4 kecamatan, yaitu Kecamatan Ploso, Jogoroto, Tembelang, dan Plandaan. 4 Kecamatan tersebut dapat dilihat memiliki persamaan karakteristik dari memiliki kesamaan dalam akses sanitasi dan pelayanan usia lanjut yang rendah sehingga berada dalam 1 kuadran. Hal ini dapat dilihat juga dari data aslinya dimana pada karakteristik sanitasi, kecamatan Ploso (97.9%), Jogoroto (93.55%), dan Tembelang (95.9%) memiliki nilai yang tinggi. Adapun Plandaan memiliki sanitasi lebih rendah (77.4%) namun dapat dikatakan bahwa mayoritas 4 kecamatan ini memiliki sanitasi yang baik. Kemudian pada karakteristik pelayanan usia lanjut dapat dilihat bahwa semua kecamatan memiliki nilai yang cukup rendah.
*Kelompok 4 (Kuadran 4 bagian kanan bawah)
Terdiri atas 7 kecamatan, yaitu Ngoro, Mojoagung, Mojowarno, Kabuh, Ngusikan, Wonosalam, dan Perak. 7 Kecamatan tersebut dapat dilihat memiliki persamaan karakteristik dari segi fasilitas tempat umum yang cukup memadai dan pelayanan usia produktif yang rendah sehingga berada dalam 1 kuadran. Sebagian besar kecamatan memiliki fasilitas tempat umum yang cukup memadai, terutama Kabuh dan Perak yang tertinggi. Kemudian kecamatan-kecamatan ini memiliki pelayanan usia produktif yang rendah, kecuali Mojoagung yang lebih tinggi dibandingkan yang lain.
Hal ini ditunjukan oleh data aslinya dimana Kabuh (85.2%) dan Perak (86%) memiliki fasilitas tempat umum tertinggi. Ngoro (66.6%), Mojoagung (61.35%), Mojowarno (66.45%), dan Wonosalam (66.7%) memiliki jumlah fasilitas tempat umum yang cukup baik. Ngusikan memiliki nilai paling rendah (59.6%). Kemudian, Perak memiliki pelayanan usia produktif terendah (1.9%). Wonosalam (18.3%), Mojowarno (20.35%), dan Ngoro (20.45%) juga tergolong rendah. Kabuh (22%) dan Ngusikan (26.7%) sedikit lebih tinggi. Mojoagung memiliki tingkat pelayanan tertinggi di kelompok ini (32.6%).
Hal di atas menunjukkan adanya distorsi yang cukup besar pada proses reduksi dimensi menggunakan Multidimensional Scaling (MDS). Distorsi ini berarti bahwa jarak antar titik dalam ruang hasil MDS tidak sepenuhnya mencerminkan jarak asli dalam ruang berdimensi tinggi.
Berikut ini sintaks lengkap Multidimensional Scaling (MDS) dari langkah 1 hingga langkah 6.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.manifold import MDS
from sklearn.metrics import pairwise_distances
# Data lingkungan dan kesehatan
data = {
"Kecamatan": [
"Bandar Kedungmulyo", "Perak", "Gudo", "Diwek", "Ngoro", "Mojowarno",
"Bareng", "Wonosalam", "Mojoagung", "Sumobito", "Jogoroto",
"Peterongan", "Jombang", "Megaluh", "Tembelang", "Kesamben",
"Kudu", "Ngusikan", "Ploso", "Kabuh", "Plandaan"
],
"X1_%Penduduk Sanitasi Layak": [
97.3, 100, 99.4, 99.3, 100, 88.05, 77.5, 62.9, 96.75, 99.35, 93.55,
99.55, 100, 94.9, 95.9, 97.6, 92.9, 93.4, 97.9, 71.8, 77.4
],
"X2_% Sarana Air Minum": [
100, 0, 85.4, 83.35, 65.7, 44.05, 75, 0, 50, 90, 66.7, 75, 85.4, 100,
71.45, 100, 100, 0, 80, 66.7, 100
],
"X3_% Tempat Umum": [
41, 86, 75.9, 57.85, 66.6, 66.45, 59.3, 66.7, 61.35, 82.8, 60.05,
83.15, 84.58, 87.8, 68.75, 66.5, 42.2, 59.6, 39.4, 85.2, 65.5
],
"X4_% Pelayanan Usia Produktif": [
33.2, 1.9, 43.15, 39.8, 20.45, 20.35, 11.1, 18.3, 32.6, 20, 38.9,
15.15, 14.375, 49.1, 56.15, 34.65, 98, 26.7, 13.9, 22, 15.5
],
"X5_% Pelayanan Usia Lanjut": [
44.6, 7.3, 55.75, 48.45, 47.05, 48.4, 106.3, 42.5, 56.65, 143.15,
39.75, 58.05, 42.425, 92.2, 35.6, 67.75, 48.9, 68.9, 48.7, 21.7, 30.1
]
}
# Membuat DataFrame
df = pd.DataFrame(data)
# Menetapkan kolom Kecamatan sebagai indeks
df.set_index('Kecamatan', inplace=True)
# Menampilkan 5 data teratas dari DataFrame
print("Data Lingkungan dan Kesehatan (5 Teratas):\n", df.head())
# Hitung matriks jarak asli dari data awal
original_distances = pairwise_distances(df, metric='euclidean')
# Menerapkan Multidimensional Scaling
mds = MDS(n_components=2, random_state=0, dissimilarity='precomputed')
scaled_df = mds.fit_transform(original_distances)
# Menampilkan hasil MDS
print("\nHasil Multidimensional Scaling:\n", scaled_df)
# Hitung matriks jarak hasil MDS
mds_distances = pairwise_distances(scaled_df, metric='euclidean')
# Hitung nilai stress secara manual
stress_manual = 0.5 * np.sum((mds_distances - original_distances) ** 2)
stress_kruskal = np.sqrt(stress_manual / (0.5 * np.sum(original_distances ** 2)))
# Menampilkan hasil perhitungan manual dan dari Scikit-Learn
print("\nNilai Stress dari Scikit-Learn:", mds.stress_)
print("Manual calculus of sklearn stress:", stress_manual)
print("Kruskal's Stress:", stress_kruskal)
print("[Poor > 0.2 > Fair > 0.1 > Good > 0.05 > Excellent > 0.025 > Perfect > 0.0]")
# Membuat scatterplot hasil MDS
plt.figure(figsize=(10, 8))
plt.scatter(scaled_df[:, 0], scaled_df[:, 1], c='blue', s=100)
# Menambahkan label pada tiap titik
for i, kecamatan in enumerate(df.index):
plt.annotate(kecamatan, (scaled_df[i, 0] + 0.3, scaled_df[i, 1]), fontsize=9)
# Menambahkan garis pemisah kuadran
plt.axhline(0, color='red', lw=1, ls='--') # Garis horizontal
plt.axvline(0, color='red', lw=1, ls='--') # Garis vertikal
# Menambahkan judul dan label sumbu
plt.title('Multidimensional Scaling (MDS) pada Data Lingkungan dan Kesehatan', fontsize=14)
plt.xlabel('Koordinat 1', fontsize=12)
plt.ylabel('Koordinat 2', fontsize=12)
plt.grid()
plt.show()
Kesimpulan
Dari hasil tutorial di atas, jika dibandingkan dengan hasil yang diperoleh dari aplikasi SPSS dalam artikel “Tutorial Multidimensional Scaling dengan SPSS #2“, terdapat beberapa perbedaan yang signifikan, baik dari segi perhitungan maupun visualisasi yang dihasilkan. Perbedaan ini dapat disebabkan oleh beberapa faktor yang berkaitan dengan metode dan parameter yang digunakan dalam masing-masing aplikasi.
Pertama, dalam penggunaan MDS di Python, sangat penting untuk menetapkan parameter dengan tepat, termasuk jenis pengukuran ketidakserasian dan nilai random_state. Parameter ini memainkan peran krusial dalam menentukan bagaimana model akan berfungsi dan hasil yang diperoleh. Misalnya, dengan mengatur random_state, kita mengontrol aspek acak dari algoritma, yang dapat mempengaruhi hasil akhir. Jika nilai random_state diubah, hasil MDS yang diperoleh bisa bervariasi, yang menunjukkan ketidakpastian dalam representasi data.
Kedua, perbedaan dalam algoritma atau metode pengolahan data yang diterapkan oleh Python dan SPSS juga dapat menjadi penyebab hasil yang berbeda. Meskipun kedua alat tersebut berfungsi untuk tujuan yang sama, yaitu pengurangan dimensi dan visualisasi data, cara mereka mengelola dan memproses data dapat bervariasi. SPSS mungkin menggunakan algoritma atau pendekatan default yang berbeda dibandingkan dengan Python, yang memungkinkan lebih banyak penyesuaian parameter.
Selain itu, aspek visualisasi juga menjadi perhatian penting. Dalam Python, hasil visualisasi biasanya dilakukan menggunakan library seperti Matplotlib, yang mungkin menghasilkan grafik dengan gaya dan parameter yang berbeda dibandingkan dengan visualisasi di SPSS. Hal ini bisa menciptakan persepsi yang berbeda tentang data dan pola yang ada.
Dengan demikian, penting untuk sobat memahami bahwa perbedaan hasil antara Python dan SPSS tidak hanya berasal dari metode penghitungan, tetapi juga dari pengaturan parameter, algoritma yang digunakan, serta cara visualisasi data. Untuk mendapatkan hasil yang lebih konsisten, sebaiknya dilakukan pemahaman mendalam tentang parameter yang digunakan dalam kedua alat, serta potensi dampaknya terhadap hasil analisis. Hal ini akan memungkinkan pengguna untuk melakukan perbandingan yang lebih akurat dan mendapatkan wawasan yang lebih dalam tentang data yang dianalisis.
Referensi
Exsight. (2023). Pengenalan multidimensional scaling. Diakses dari https://exsight.id/blog/2023/09/06/pengenalan-multidimensional-scaling/
Exsight. (2023). Tutorial multidimensional scaling dengan SPSS. Diakses dari https://exsight.id/blog/2023/09/25/tutorial-multidimensional-scaling-dengan-spss-2/
Stack Overflow. (n.d.). Stress attribute sklearn.manifold.MDS Python. Diakses dari https://stackoverflow.com/questions/36428205/stress-attribute-sklearn-manifold-mds-python
Statology. 2022. Multidimensional scaling in Python. Diakses dari https://www.statology.org/multidimensional-scaling-in-python/
Sampai di sini dulu penjelasan terkait “Multidimensional Scaling (MDS) dengan Python“. Apabila sobat Exsight masih ada yang dibingungkan terkait pembahasan pada artikel ini, bisa langsung saja ramaikan kolom komentar atau hubungi admin melalui tombol bantuan di kanan bawah. Stay tuned di website https://exsight.id/blog/ agar tidak ketinggalan artikel-artikel menarik lainnya. See you in the next article yaa!

Certified Russian translation services in the UK play a crucial role in helping individuals and businesses overcome legal, academic, and bureaucratic hurdles by ensuring documents are accurately translated and officially recognized. Whether you’re applying for a visa, enrolling in a UK university, submitting legal documents to a court, registering with the GMC, or entering into a business contract, certified translations are often a legal requirement—not just a helpful extra. They provide more than just word-for-word translation; they ensure precision, cultural and legal accuracy, and compliance with UK-specific standards. For instance, a simple mistake in translating a diploma or marriage certificate can lead to visa delays, legal issues, or lost opportunities. Certified translators understand the context behind every document, from “доверенность” meaning “power of attorney” to interpreting Russian academic terms for British institutions, and they offer a Certificate of Accuracy that UK authorities demand. These services also ensure privacy and data protection, especially for sensitive materials like medical records or financial statements. As seen in real-life cases, such as a Russian architect whose job prospects hinged on correctly certified qualifications, choosing professional translation can mean the difference between rejection and success. From passports to engineering blueprints, certified translations open doors—quietly but powerfully—in education, law, healthcare, and international business. Learn more or get expert help at memoir translation from russian to english in the uk
Discover elegant comfort and modern design with JASIWAY’s premium furniture collection. Our JASIWAY sofa beds combine style and versatility, perfect for any living space. Choose a sofa bed that transforms effortlessly for guests or relaxation. Enhance your space with a JASIWAY coffee table, a centerpiece of style and function, or select a classic coffee table for daily convenience. Organize with elegance using a JASIWAY dressing table, crafted for beauty and utility—your ideal dressing table solution. For sleek entertainment setups, our JASIWAY TV stands deliver both storage and sophistication—find your perfect TV stand here. Redefine your lounge area with a JASIWAY sofa, designed for lasting comfort and refined living. Choose a sofa that completes your home with flair and function. Shop JASIWAY—where furniture meets lifestyle.